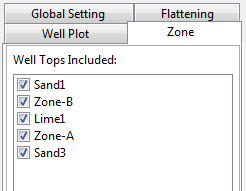
All Safira Digitizer task can simply be accessed by the toolbar as shown above.
- Creating New Project
Creating new project is one of the simplest task in Safira Digitizer. It will close the existing opened project and start with new blank project. To do that, simply click the toolbar “New Project” or menubar File-New Project. - Opening Existing Project
This will open the saved Safira Digitizer project (*.sfd). Click toolbar “Open Project” or menubar File-Open Project” and browse to the saved file. To test whether Safira Digitizer correctly running or not, you can open sample projects exists in folder “samples”. - Saving Project
Saving the project can be done by clicking toolbar “Save Project” or “Save Project As” or its menubar. You will be prompted to choose a new project filename. - Importing image
Importing image in most cases is the first important step to start digitizing. Click toolbar “Import Image” and browse existing image to be digitized. The file format could be *.png, *.bmp, *.gif, or *.jpeg”. Once it is imported, the image will be plotted in the view panel. - Calibrating Image
Calibrating image is a process to make Safira Digitizer understand the real coordinate of the image. Without calibration, Safira Digitizer will directly use the exact value from the screen coordinate. Therefore, the result might be away different from the real coordinate. This calibration can be done by clicking toolbar “New Calibration” and calibration dialog will be shown up. You must read carefully the notes in the bottom part of the dialog as follows:To calibrate the coordinate:
1. Make sure the imported image is on correctly horizontal position.
2. Select 2 points (X1,Y1) and (X2,Y2) that have different X values and Y values as like as above sample picture.Those notes should clearly explain how to do the next procedure.. Just click OK and select 2 coordinate for calibration. To ease the calibration, it is suggested to select 2 points that is located at the maximum value of X and Y, for example at (0,Ymax) and (Xmax, 0). Once the 2nd point is clicked, this following message box should be prompted.
Click Ok and go to setting panel to change the real X and Y values of those 2 selected points.
- Setting Up the View
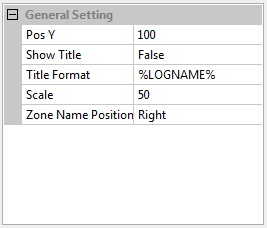
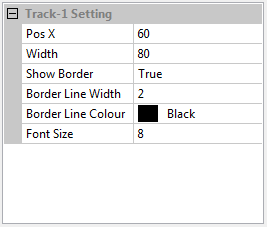
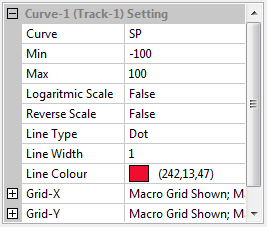
The following value in the setting panel can be adjusted to change the appearance of the viewer panel.- Bitmap Angle
Changing this value will rotate the bitmap as the value of angle. This is important in some condition where the image is not exactly positioned at horizontal position. - Show Grid
It is intended to change the grid plot in the viewer plot. It can be selected between “both”, “X-Axes”, “Y-Axes”, or “None” - X-Axes Scale
It is a choice of linear or logarithmic scale for X-axes. - Y-Axes Scale
It is a choice of linear or logarithmic scale for Y-axes. - Decimal
It is the precission value to be shown. The higher the value the more precise the number. - Package Shown
It is a choice whether to show only the selected package or to show all packages.
- Bitmap Angle
- Creating Data Package
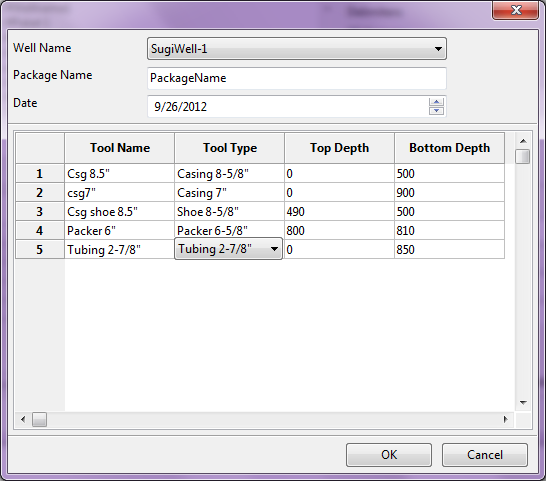
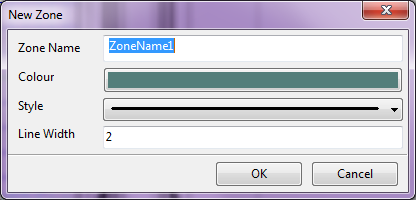
Data package is a group / table that can contain many of points picked from the image. A project file can contain many data packages. To create a package, click toolbar “Add Package” and give a name of the package. It must be noted that you cannot pick any points from the point unless a package has been created. - Deleting Data Package
Deleting package is certainly to remove a package from the project. It can be done by selecting the package and click toolbar “Delete Package”. - Picking Data
After creating new package, you can start picking points in the viewer panel. To do that, first you have to click button “Pick Mode” and that click inside the viewer panel. A new point clicked will automatically generated inside the Data Package table. - Editing Data
- Insert New Points
To insert new point between data in a package, first, you have to select a row in the data package table. The selected point will be highlighted in the viewer panel. Next step, click button “Pick Mode” and click new point to be inserted after the highlighted point. - Deleting Points
Similar to insertion, first you have to select rows to be deleted inside the data table, and then simply click Del in your keyboard.
- Insert New Points
- Exporting Data
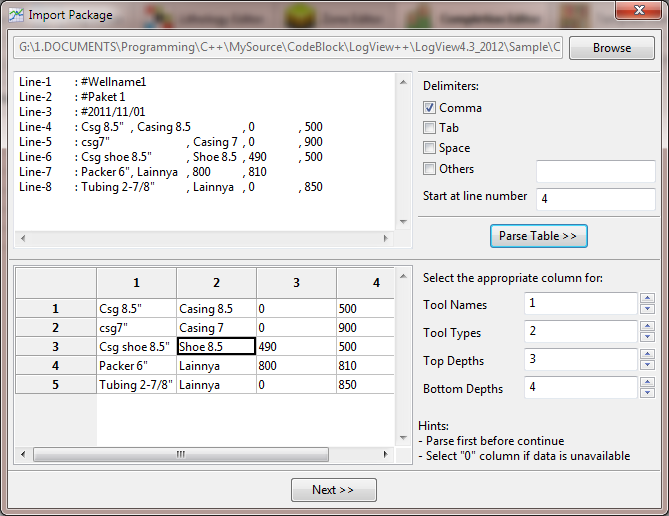
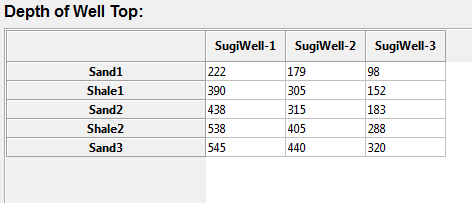
Exporting data is one of the most important step in Safira Digitizer. It will export all packages and points inside the package as a text file. After that, it can be imported to other program i.e EXCEL for further usage / calculation. To do that, click toolbar “Export Data” and fill the new filename to dump the data. The exported file should be formated like this:Those exported data contains 2 packages (Curve-1 and Curve-2) and each package has its a bunch of real X and Y values.